Stop Letting LLMs Orchestrate Your AI Agents
Running a single AI coding agent interactively is straightforward. The challenge starts when a team needs multiple agents: Claude Code, Codex CLI, Gemini CLI, etc. working together in automated pipelines that must run reliably every time. At that point, every team faces the same architectural fork: do we let an LLM orchestrate the agents, or do we write code that orchestrates them?
The evidence for this article comes from four multi-agent systems I built: Planora (a multi-agent implementation planning tool that outperforms Claude Code’s native plan mode; scoring 87 vs 61 in blind LLM as a judge benchmarks by having Claude generate an implementation plan, then Gemini and Codex audit it independently in parallel, and Claude refine based on their findings), an article research pipeline with asset generation, a multi-agent performance audit and code review system where five agents (Claude, Codex, Gemini, and OpenCode with two different providers) audit across eight performance categories in parallel, and Raven (built on an enhanced version of the Ralph loop, the ~80-line bash script that reached 14K GitHub stars for running Claude Code autonomously until a PRD is complete). The original Ralph is minimal: spawn a fresh agent, pick the next task, implement, commit, repeat. My version extended it with git commit recovery, rate-limit detection with timezone-aware cooldown parsing, exponential backoff schedules, phase-based task progression, and multi-agent support for both Claude and Codex.
By the fourth system, I noticed that 60-70% of the orchestration code was identical across all four projects. Subprocess management. Stream parsing. Rate-limit recovery. Stall detection. Resume logic. I had been rebuilding the same infrastructure every time, and each time, making the same fundamental architectural decision without realizing it.
This article compares interactive and headless orchestration across four dimensions, reliability, prompt control, observability, and cost, using real failure data from GitHub issues and patterns from these four systems. It also covers a third option: an orchestration engine that packages the headless approach as a reusable library.
The Spectrum: Three Modes
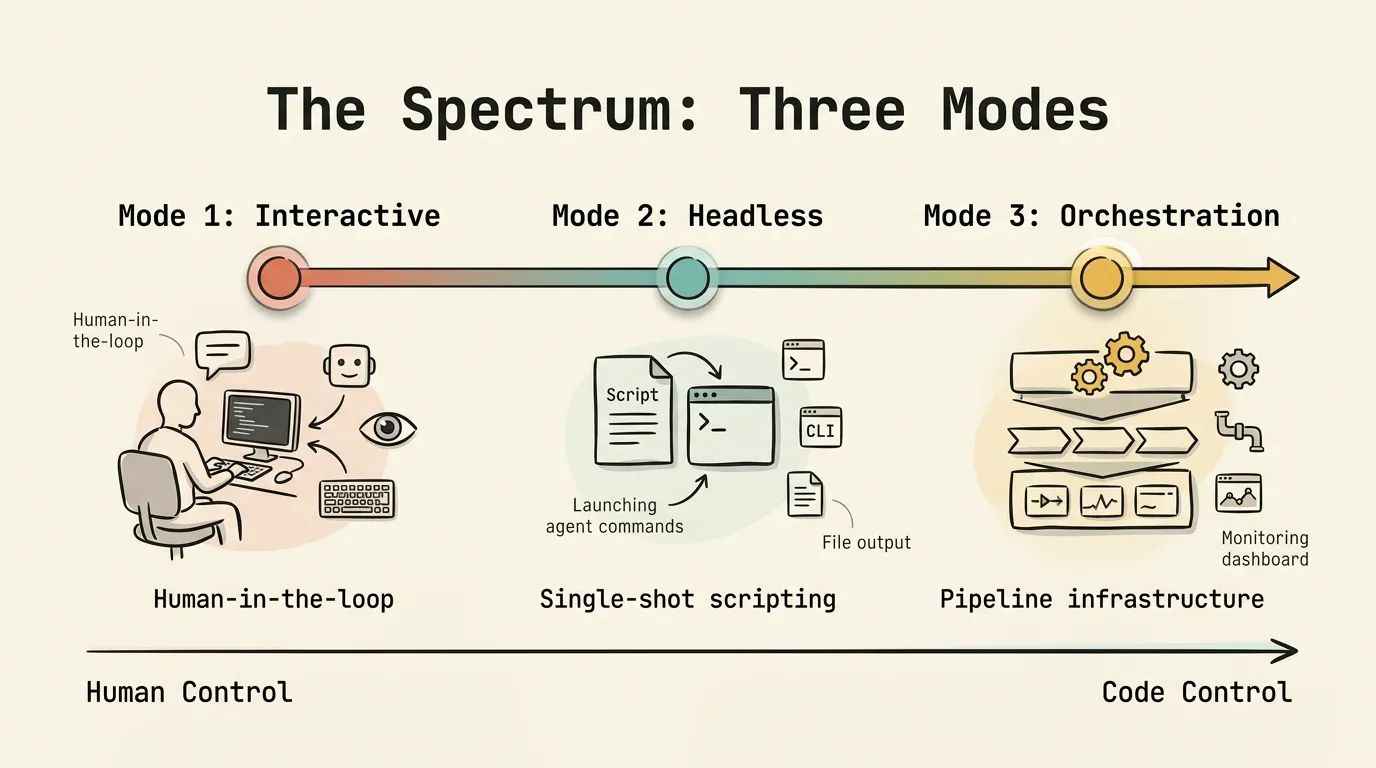
When people talk about “running AI agents,” they are usually conflating three distinct modes of operation.
Mode 1: Interactive. Human-in-the-loop. You sit in a Claude Code session, a VS Code Copilot chat, or a Codex CLI session, type instructions, and the agent responds so you can course-correct in real time. If you want the agent to delegate, you use subagent .md files, slash commands, or the Agent tool to spawn sub-sessions. The orchestration logic lives in the LLM’s reasoning: you describe what you want and hope it follows through.
Mode 2: Headless. Single-shot scripting. You invoke an agent CLI with the -p flag (claude -p "do this", codex exec "do that", gemini -p "analyze this") and capture the output. The agent runs to completion without human interaction. A bash script or Python script strings multiple invocations together. You control the flow; the agents just execute.
Mode 3: Orchestration Engine. The leap from Mode 2 to Mode 3 happens when headless scripts get complex enough to need real infrastructure. Multi-phase pipelines with dependency ordering. Parallel execution with concurrency limits. Stream monitoring that parses JSONL output from five different agent formats. Rate-limit detection with timezone-aware reset time parsing. Phase-level resume so a failure at step 4 doesn’t force re-running steps 1-3.
Most teams start at Mode 1, realize they need automation, jump to Mode 2, and then gradually discover they need Mode 3 as their pipelines get more ambitious. The question is whether Mode 1 can grow into a real orchestration system, or whether Mode 2 is the only viable foundation.
Two Ways to Build Orchestration
A concrete pipeline: Plan (1 agent) → Audit (N agents in parallel) → Refine (1 agent) → Report (archive results).
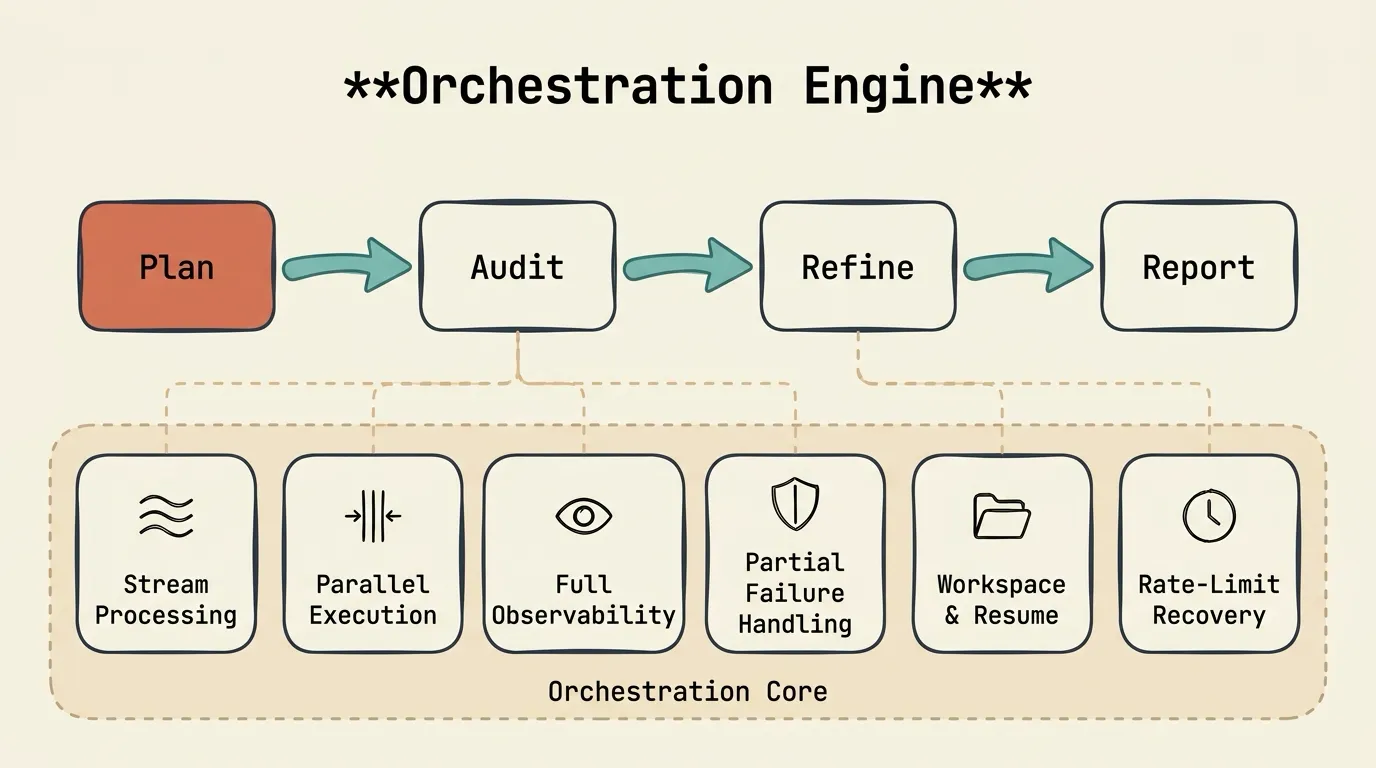
In Planora, the plan phase uses Claude to generate a structured 12-section implementation spec covering critical files, implementation steps, testing strategy, risks, and verification checklists. The audit phase runs Gemini and Codex in parallel to independently review it across 10 categories: missing steps, security gaps, performance issues, edge cases, better alternatives. The refine phase feeds the audit findings back to Claude for revision. The report phase archives everything. In blind LLM-as-a-judge benchmarks, this multi-agent approach scored 87 versus 61 for Claude Code’s native plan mode.
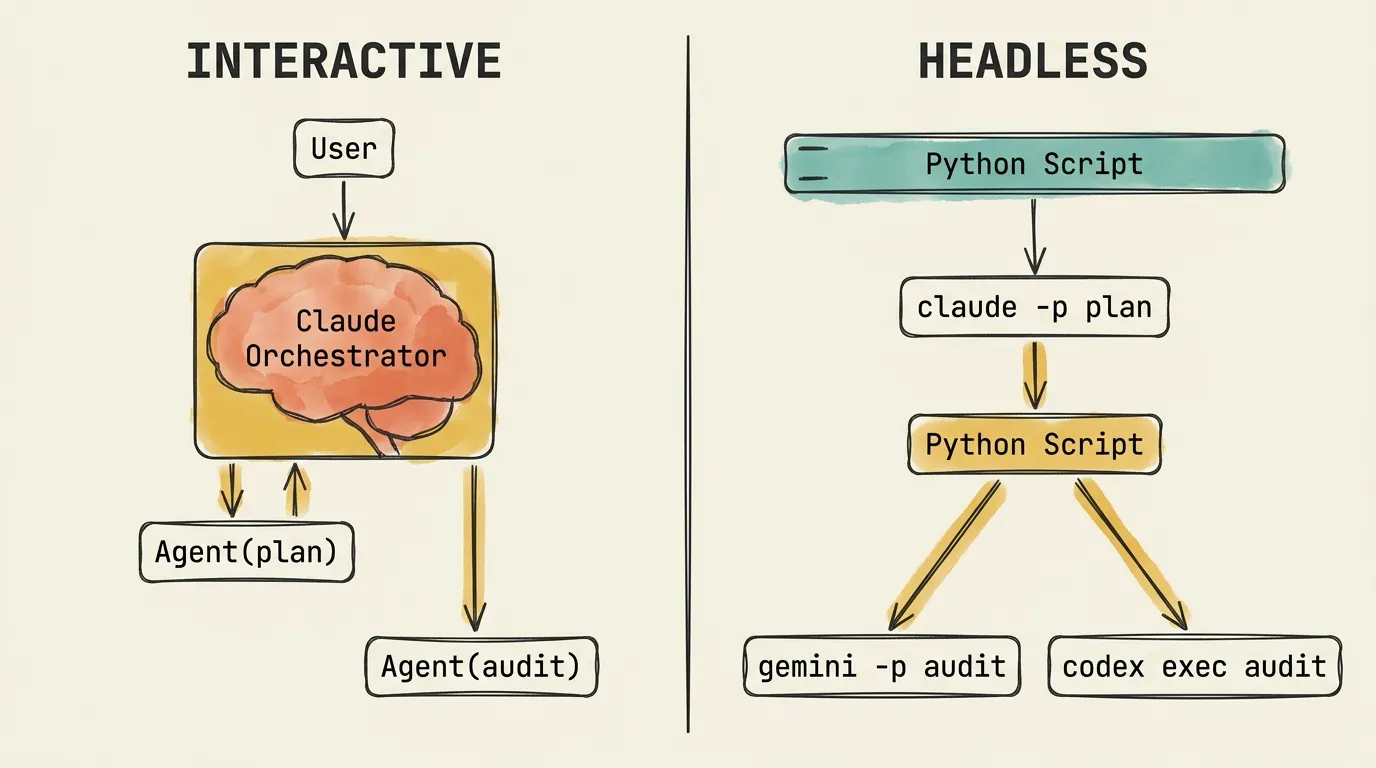
Interactive approach. You open a Claude Code session and describe the pipeline. Claude spawns a subagent for the plan phase via the Agent tool, reads its output, then spawns audit subagents, reads their output, and spawns a refine subagent. The orchestration logic is LLM reasoning: Claude decides when to delegate, what prompt to write for each subagent, and how to handle the results.
The flow: User → Claude interprets → Claude crafts delegation prompt → Subagent executes.
Headless approach. A Python script defines the pipeline as code. It launches claude -p "create an implementation plan for..." as a subprocess, captures the output, then launches gemini -p "audit this plan..." and codex exec "audit this plan..." in parallel as separate subprocesses. It captures their output, feeds it into another claude -p "refine this plan based on..." invocation, and archives the results.
The flow: Python script → Jinja2 template → Exact prompt string → Agent CLI executes.
Same pipeline, same outcome. The execution models have almost nothing in common.
Reliability and Determinism
Data from my four orchestration systems and Claude Code’s GitHub issue tracker:
- ~40% background output retrieval failure rate for subagents running in parallel
- 0% guarantee that the orchestrating Claude session will actually spawn subagents as instructed
- 14+ open GitHub issues on Agent tool reliability
- 100% prompt delivery determinism in headless mode (because it’s just
subprocess.exec)
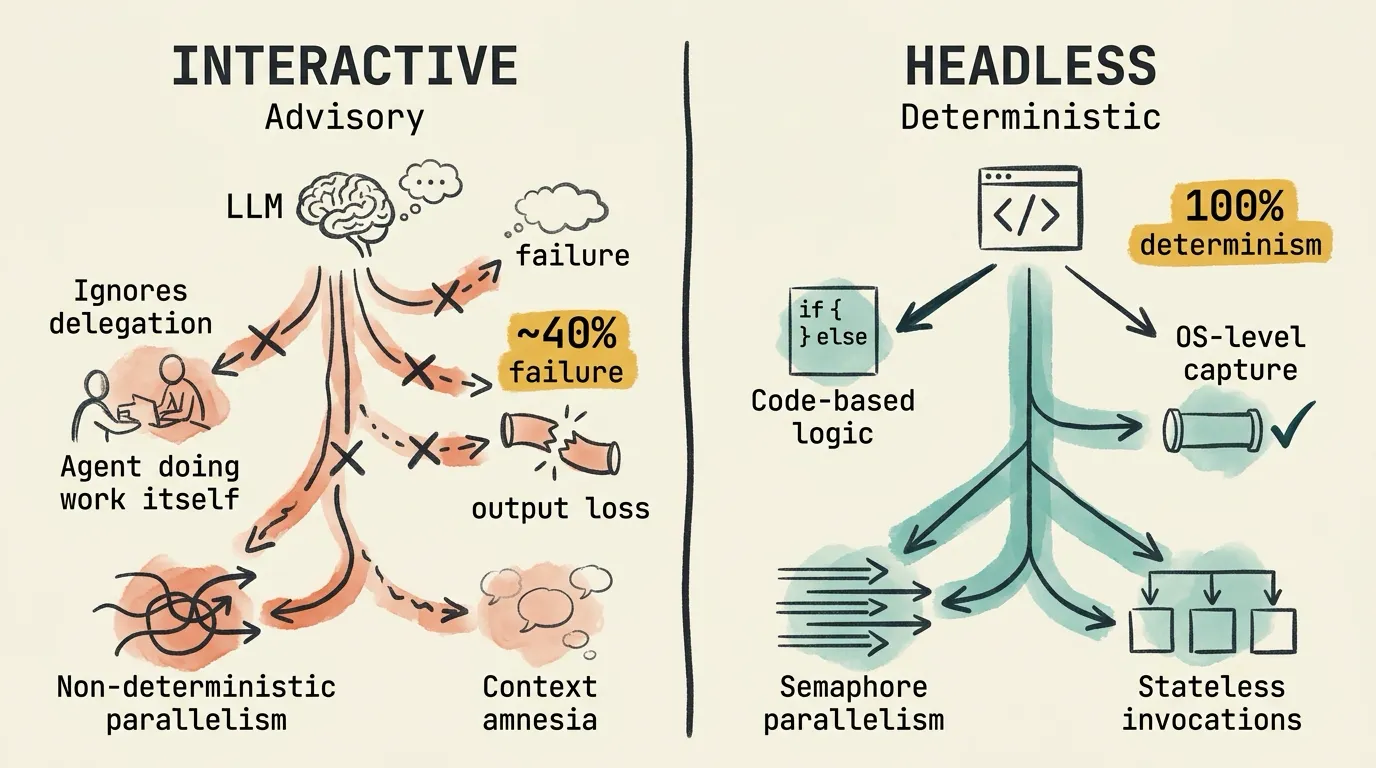
The interactive failure modes are real.
The agent ignores delegation instructions. You tell Claude: “Spawn a subagent to create the plan using the plan template.” In some runs, Claude ignores the instruction entirely and writes the plan itself, using its own context, without spawning any subagent. The 12-section plan contract? Not enforced. The Jinja2 template? Never used. This is documented as a consistent pattern: Claude routinely ignores explicit instructions to delegate via the Agent tool, choosing to do the work itself instead.
Background output loss hits ~40%. Even setting aside the multi-provider limitation (interactive mode can only spawn Claude subagents, not Gemini or Codex), the output retrieval for the subagents it can spawn is unreliable. In one 5-agent session, 2 out of 5 agents had output retrieval failures: one returned empty content, another returned raw JSON instead of a summary. That’s a small sample, but the pattern is consistent with other reports in the issue tracker. When a pipeline depends on collecting results from multiple subagents before moving to the next phase, even occasional retrieval failures mean the downstream phase works with incomplete data. The orchestrator may not even notice what’s missing.
Parallelism is non-deterministic. Agent tool calls must be in a single assistant message for parallelism, but Claude may choose to run them sequentially across messages. You can’t enforce parallel execution, only suggest it.
Context compaction destroys team state. In long orchestration sessions, Claude’s context window fills up and gets compacted. After compaction, the lead agent completely loses awareness of team members. A carefully orchestrated multi-agent pipeline forgets it has agents.
None of these failure modes exist in headless orchestration. The architecture makes them structurally impossible. Pipeline logic is if/else, loops, semaphores, and error handling in Python: it runs identically every time. Output is captured through stdout/stderr piped to files, with exit codes from asyncio.subprocess, not internal message passing. Parallelism is enforced by asyncio.Semaphore, not suggested to an LLM. And each agent subprocess is independent and stateless: no context accumulation, no compaction, no state loss between phases. Phase 3 doesn’t know or care that Phase 1 happened. It just reads the output file.
Prompt Control and Multi-Provider Support
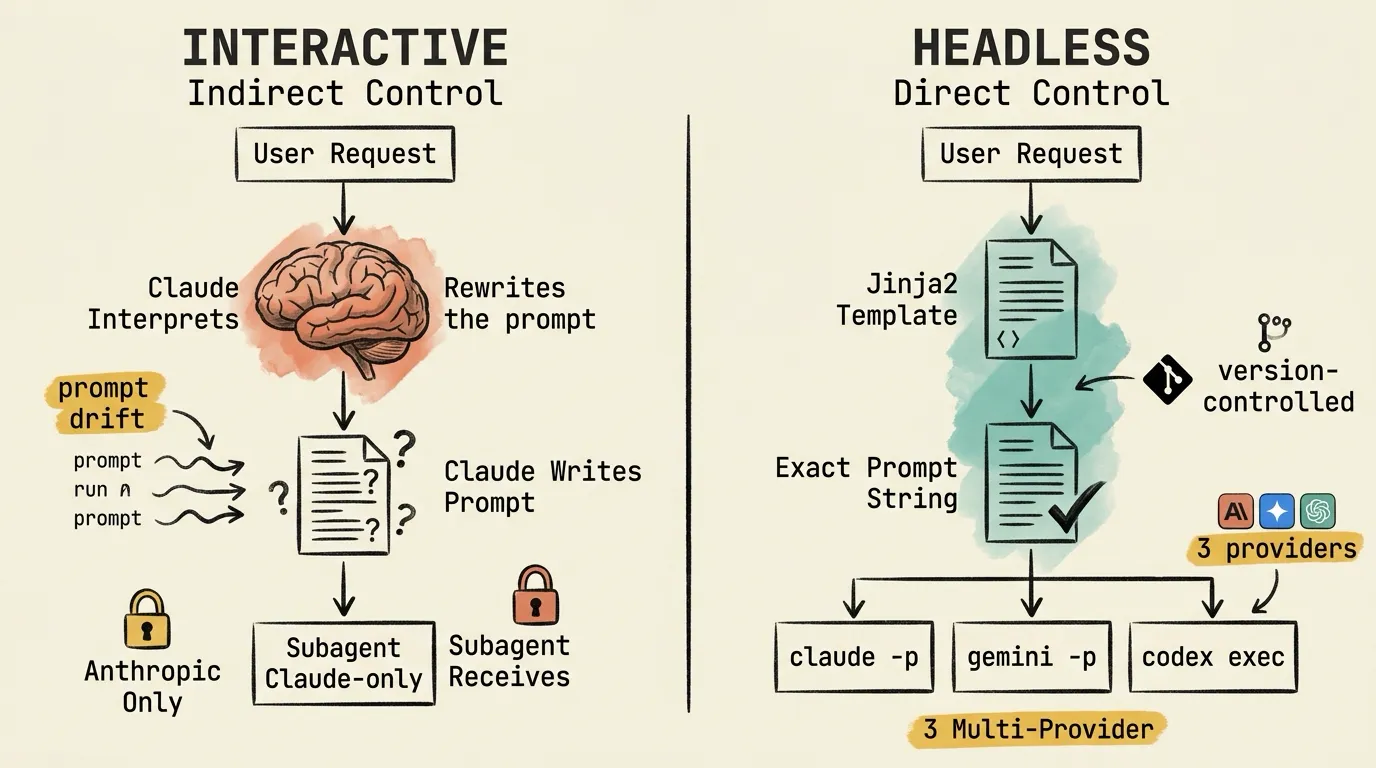
In interactive mode, there’s an LLM sitting between you and the subagents. You tell Claude what you want the subagent to do. Claude interprets the request, crafts a task prompt, and sends it to the subagent. You control the system prompt (via the subagent’s .md file), but the task prompt, the actual instructions the subagent receives, is Claude-crafted.
You can’t inspect this prompt at runtime or guarantee it includes specific structural requirements. If you need the audit to cover exactly 10 categories, Claude might rephrase that into 8, combine two categories, or add one it thinks is relevant. The prompt drifts across runs.
There’s also a hard constraint: interactive mode only supports Anthropic models. Claude can only spawn Claude subagents. If a pipeline needs Gemini for large-context analysis and Codex for code generation, it’s architecturally impossible in a single interactive session.
Headless mode flips this completely. The prompt is a string you control:
claude -p "exact prompt"
codex exec "exact prompt"
gemini -p "exact prompt"No intermediary LLM rewriting the instructions. I use Jinja2 templates with structural contracts: a plan template has 12 required sections, an audit template has 10 required categories. Same template, same prompt structure, every run. The templates are version-controlled, diffable between runs.
Multi-provider support is trivial. Each subprocess can be any agent CLI on PATH. Planora uses Claude for planning, Gemini + Codex for audit, all in the same pipeline. The orchestration layer doesn’t care which binary it launches. It just needs to know the stream format for parsing output.
Debugging, Resume, and Observability
Production pipelines fail. What matters is what you can do about it.
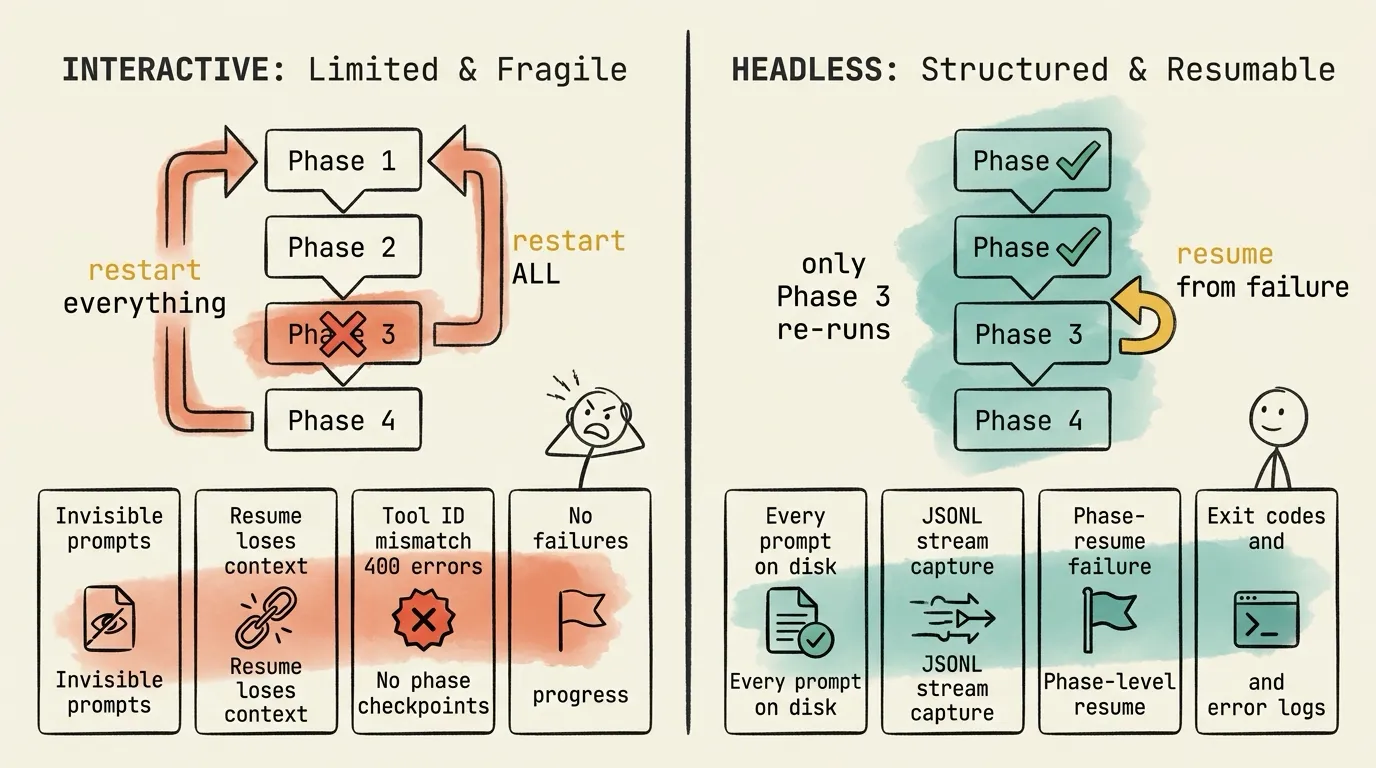
I’ll start with headless this time, because the debugging story is short: the headless approach gives you a full observability stack by default.
Every prompt is a file on disk. Version-controlled. Diffable between runs. You know exactly what every agent saw.
JSONL streams capture every event. Tool calls, state changes, costs, tokens, all written to stream files in real time. A 4-stage processing pipeline (Filter → Parse → Monitor → Stall Detect) normalizes output from five different agent CLI formats into a unified event stream.
Phase-level resume is built in. resume_from="audit" detects completed phases and re-runs only what failed. Workspace artifacts persist between runs. If 2 of 3 auditors succeeded, those results are preserved. Only the failed auditor re-runs.
If an agent fails mid-execution: exit code captured, error logged, phase marked as failed. The pipeline can retry with exponential backoff, skip the phase, or halt cleanly. Other phases’ artifacts remain intact.
In interactive mode, the observability surface is whatever Claude decides to tell you. In headless mode, it is the OS itself: files, streams, exit codes, process state.
When something goes wrong, you can’t inspect subagent prompts at runtime. The prompt Claude crafts for subagents is invisible unless you dig into ~/.claude/projects/.../subagents/agent-*.jsonl transcript files after the fact. By then it’s too late to intervene.
Resume is fundamentally broken. Not opinion. It’s documented across multiple GitHub issues:
- Resume loses user prompts
- Resume forks instead of accumulating context
- Tool use ID mismatch causes 400 errors
- Large sessions crash on resume
If a subagent fails mid-execution, you restart the entire session. There is no phase-level checkpoint. The orchestrator LLM may not even reproduce the same delegation pattern on the next run. The plan phase runs again, wasting time and tokens, even though it already succeeded.
Cost, Token Efficiency, and Parallelism
Where do tokens actually go?
In interactive orchestration, the main Claude session spends tokens on reading subagent results back into its context, reasoning about what to do next, crafting delegation prompts, and tracking pipeline state. All of that is coordination overhead. The Python code that makes the same decisions costs zero tokens. The multiplication gets worse with parallelism: a 3-agent team uses roughly 3-4x the tokens of a single session doing the same work sequentially. Each subagent gets its own 200K context window, and the orchestrator must ingest all their outputs. All parallel subagents also share the same rate limit pool, so you pay more and get less reliable results.
Headless mode spends zero LLM tokens on coordination. 100% of tokens go to actual agent work. Each subprocess specifies its own --model flag, so model tiering is trivial: Opus for planning, Sonnet for auditing, Haiku for quick checks. And because different providers have separate rate limits, Claude, Gemini, and Codex running as OS processes don’t compete for the same API quota.
The Scorecard
After running both approaches across four production systems, here is my assessment across 11 dimensions:
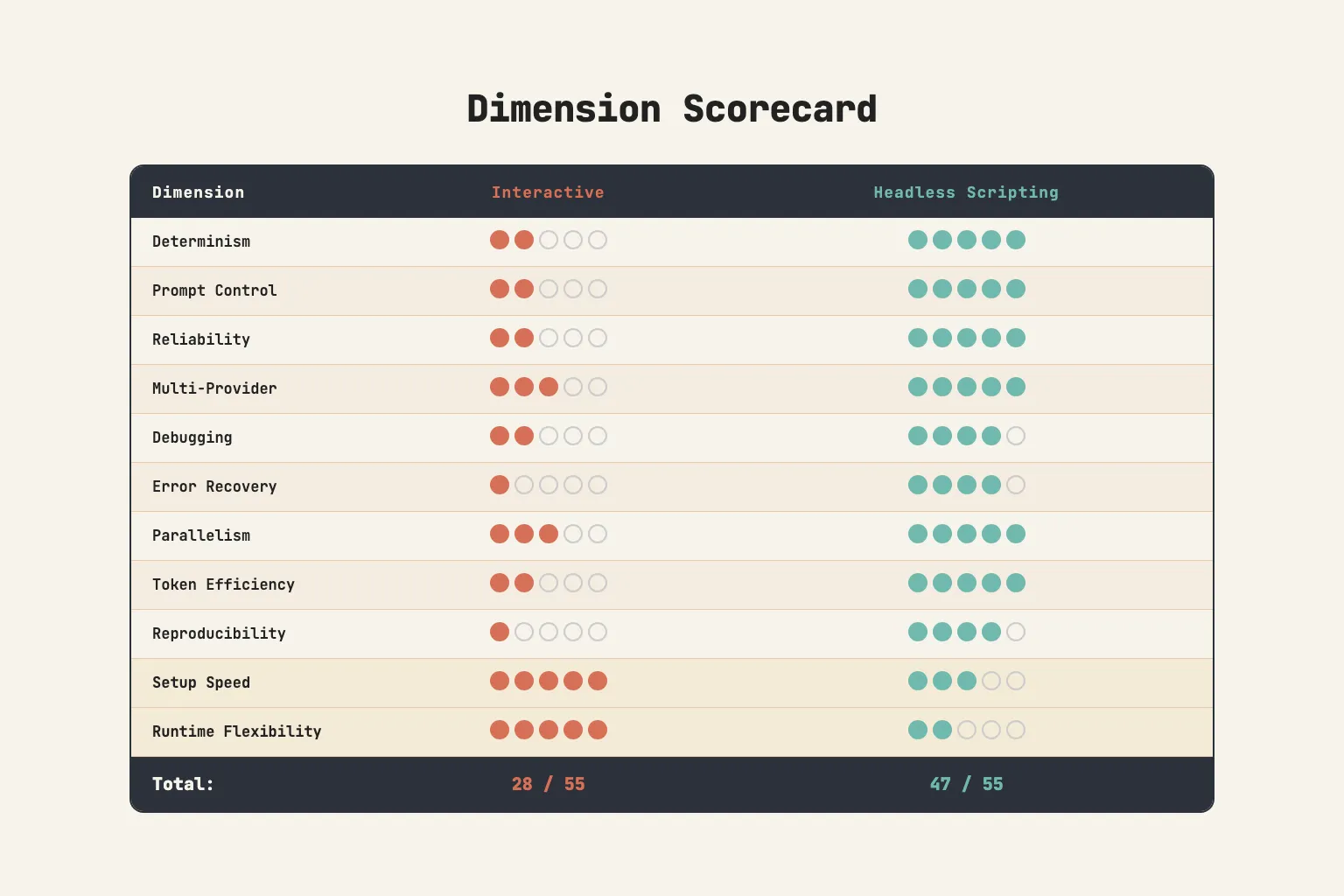
Interactive wins on two dimensions: setup speed (write .md files and slash commands, start in minutes) and runtime flexibility (the LLM adapts dynamically to unexpected situations). These are real advantages that matter for exploratory work and rapid prototyping.
Headless wins everywhere else: determinism, reliability, prompt control, error recovery, cost efficiency, reproducibility, and multi-provider support.
The scorecard makes the case for headless. But building the same headless infrastructure from scratch for every project is wasteful, which is how I ended up building orchcore.
orchcore: The Reusable Orchestration Core
After building the same headless orchestration infrastructure four times, I extracted the common layer into a standalone library: orchcore.
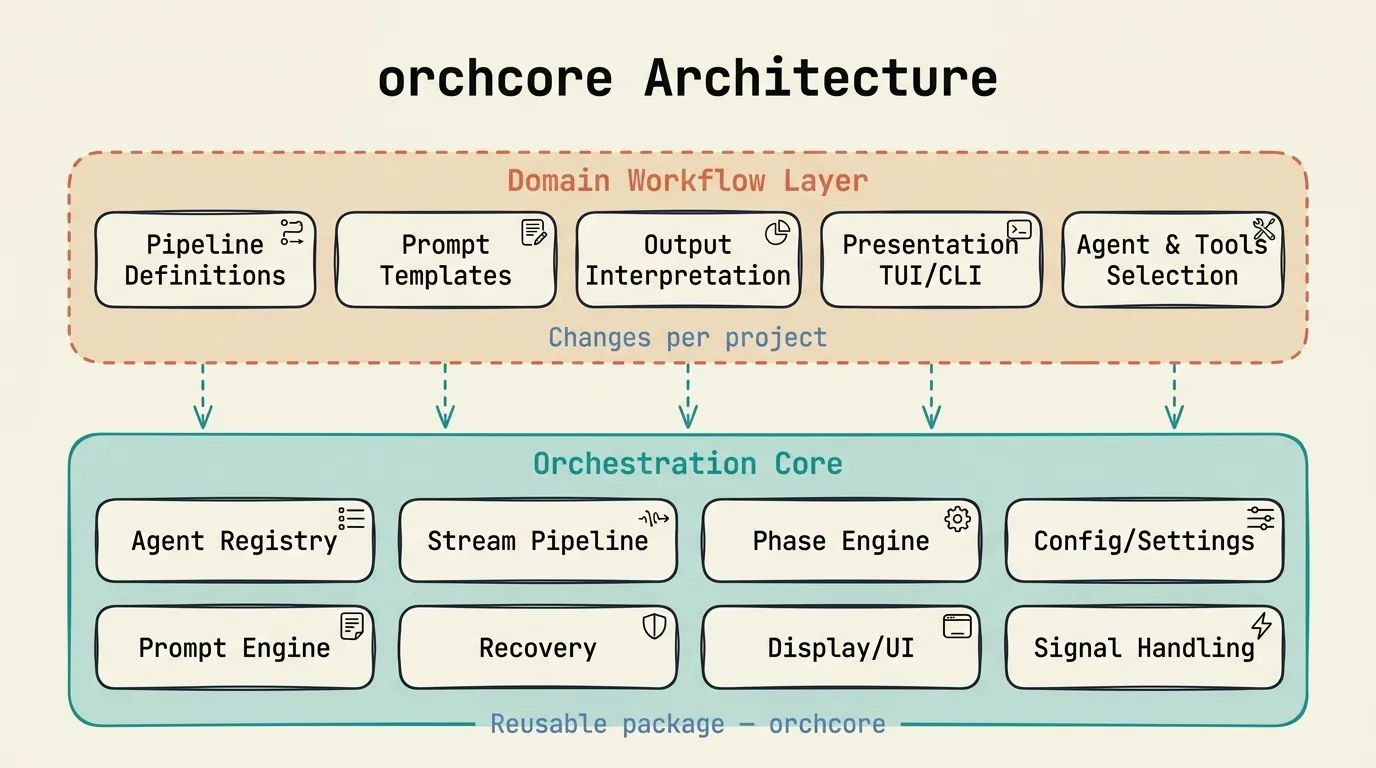
The architecture has two layers.
Domain Workflow Layer (changes per project). Pipeline definitions, prompt templates, output interpretation, presentation (TUI/CLI), agent and tool selection. This is where Planora’s implementation planning logic lives, or the articles pipeline’s research and writing phases, or the performance audit system’s review workflows. Every project defines different phases, different prompts, different agents.
Orchestration Core Layer (reusable package). This is orchcore, the infrastructure that was identical across all four systems.
AgentRegistry. Built-in agent configurations for Claude, Codex, Gemini, Copilot, and OpenCode work zero-config. Each config specifies the binary, model, subcommand, stream format, mode-specific flags, output extraction strategy, timeouts, and environment variables. New agents are added via TOML with zero code changes:
[agents.my-custom-agent]
binary = "my-agent"
model = "custom-model"
stream_format = "jsonl"4-Stage Stream Pipeline. Every agent CLI emits output differently. The stream pipeline normalizes it all:
StreamFilter: Fast-path noise reduction using string matching (no JSON parsing). Drops ~95% of JSONL lines before they reach the parser. Format-specific skip patterns per agent type.StreamParser: Converts 5 agent CLI formats into unifiedStreamEventinstances. Handles tool invocations, text content, cost/token data, exit codes.AgentMonitor: Real-time state machine with 9 states: STARTING → THINKING → WRITING → TOOL_RUNNING → STALLED → RATE_LIMITED → COMPLETED → FAILED → CANCELLED. Tracks active tools, tool counters, costs, tokens.StallDetector: Injects synthetic STALL events when agents idle beyond timeout. Two tiers: normal operations (300s) and deep tools like web research (600s).
PipelineRunner + PhaseRunner. DAG-based phase execution. Validates that phase dependencies form a valid directed acyclic graph. Supports resume from checkpoint: skip already-completed phases when re-running after a failure. Phases run agents sequentially or in parallel with asyncio.Semaphore-gated concurrency.
Recovery infrastructure. RateLimitDetector identifies rate-limit messages across all agent types using regex patterns. ResetTimeParser extracts wait times from rate-limit messages, including absolute times with timezone awareness (e.g., “resets 7pm Europe/Berlin”). RetryPolicy provides configurable backoff schedules with jitter. GitRecovery auto-commits or stashes modified files before retry attempts to ensure a clean working state.
UICallback Protocol. 14+ typed callback methods decouple the orchestration engine from any specific presentation layer:
class UICallback(Protocol):
def on_pipeline_start(self, ...) -> None: ...
def on_phase_start(self, ...) -> None: ...
def on_agent_event(self, event: StreamEvent) -> None: ...
def on_stall_detected(self, ...) -> None: ...
def on_rate_limit_wait(self, ...) -> None: ...
def on_agent_complete(self, result: AgentResult) -> None: ...
# ... 8+ more typed eventsPlanora implements this with a Textual TUI dashboard. The articles pipeline uses a Rich CLI. CI/CD runs use NullCallback (silent) or LoggingCallback (structured JSON). orchcore imports zero UI frameworks. The consuming project brings its own presentation layer.
Layered Configuration. Settings resolve through a priority chain: CLI flags → environment variables (ORCHCORE_*) → .env files → project TOML (orchcore.toml) → user TOML (~/.config/orchcore/config.toml) → pyproject.toml [tool.orchcore] → built-in defaults. Named profiles enable switching between “fast” and “deep” modes:
[profiles.fast]
max_retries = 1
stall_timeout = 60
[profiles.deep]
stall_timeout = 900
deep_tool_timeout = 1800The result: when I started Raven/Ralph (the fourth system), the orchestration setup took hours instead of weeks. Define the phases, write the prompt templates, implement a UICallback, and the rest (subprocess management, stream parsing, rate-limit recovery, stall detection, resume logic) came from orchcore.
I open-sourced orchcore. If any of this infrastructure sounds like what you’re rebuilding right now, you can install the package from PyPI using uv pip install orchcore, check out the code on GitHub, or see the full documentation.
When to Use Each Approach
The answer isn’t “headless is always better.”
Interactive orchestration makes sense for exploratory work where you don’t know the steps yet and need the LLM to help figure them out. It’s the right choice for rapid prototyping, for small-scale tasks with 1-2 subagents, for human-in-the-loop workflows where you want to steer between steps, and for one-shot tasks that aren’t repeatable pipelines. The setup speed is hard to beat. Write a .md file, add a slash command, and you’re orchestrating in minutes. When you’re still figuring out what the pipeline should look like, having an LLM that adapts dynamically to unexpected situations is a genuine advantage.
Headless scripting is for production pipelines that must run reliably every time. Multi-provider setups where Claude, Gemini, and Codex participate in the same run. Pipelines that need reproducibility, phase-level resume, retry with backoff, cost efficiency through model tiering, and stream-level observability.
Interactive orchestration is great for discovering what a pipeline should be. Headless scripting is how you run it once you know.
The Production Reality
There’s a pattern I keep seeing. Teams start with interactive mode because it’s easy, hit reliability problems as their pipelines grow, bolt on workarounds (retry the session, add more explicit instructions, parse the output and hope), and then realize they need to rewrite the orchestration layer in code.
The unreliable output retrieval, the non-deterministic delegation, the broken resume, the context compaction. These are not bugs that will be fixed next quarter. They’re inherent to the architecture. When orchestration logic lives in an LLM’s reasoning, you’re asking a probabilistic system to behave deterministically.
Interactive mode isn’t bad. It’s the wrong tool for production multi-agent pipelines, the same way a REPL is the wrong tool for a CI/CD pipeline. Both are useful. They belong in different parts of the workflow.
orchcore is my attempt to make the headless architecture reusable. Whether you use it or build your own, the underlying lesson is the same: orchestration is a code problem, not a prompting problem. I had to build it four times before that fully sank in.
References
- Anthropic, “Run Claude Code programmatically (Agent SDK docs)”: https://code.claude.com/docs/en/headless
- arxiv 2603.20847, “Engineering Pitfalls in AI Coding Tools: 3,800+ Bug Analysis”: https://arxiv.org/html/2603.20847
- bradAGI, “awesome-cli-coding-agents: 80+ agents and 20+ orchestration tools”: https://github.com/bradAGI/awesome-cli-coding-agents
- Stack Overflow Blog, “Are bugs and incidents inevitable with AI coding agents?”: https://stackoverflow.blog/2026/01/28/are-bugs-and-incidents-inevitable-with-ai-coding-agents/
- Addy Osmani, “Top AI Coding Trends 2026”: https://beyond.addy.ie/2026-trends/
- SFEIR Institute, “Headless Mode and CI/CD with Claude Code”: https://institute.sfeir.com/en/claude-code/claude-code-headless-mode-and-ci-cd/
- orchcore, “Reusable orchestration core for multi-agent CLI pipelines”: https://github.com/AbdelazizMoustafa10m/orchcore